
With time, my collection of principles become like a collection of recipes for decision making.
Elasticsearch is based on an open source called Apache Lucene. However, the Lucene is a very complicated library that needs Java to apply. Elasticsearch, on the other hand, encapsulates the complexity with simple REST API.
Compared to other NoSQL databases, such as MongoDB, Cassandra, and Redis, etc. The following features make Elasticsearch standout.
- Firstly, the ELK(elasticsearch, logstash, and kibana) stack combined data storing, data cleaning, visualization and together. You don’t need to build up and maintain your own applications to do those works.
- Secondly, the X-Pack plugin does have the monitoring, graphing as well as machine learning tools that help your dig more into your data.
- Thirdly, you can quickly and easily search a large amount of text with wildcards or regular expression. Think about you want to find specific sentences or words in millions of books. I don’t think other NoSQL database could provide an easy way to search on a user-friendly GUI to help you get the results in minutes. However, Kibana search bar, you can just right down a very simple query and get what you want immediately.
- Fourthly, full-test search. Inerted index and inverted file
Although ELK stack has lots of good features, you still need to consider how to consume your data, what kind of data you have and how frequently you update your data or schema, while you are choosing a database. In my opinion, elasticsearch is more suitable for text mining.Here is a blog that introduce the use of elasticsearch in text mining: Text Classification made easy with Elasticsearch.
Elasticsearch infrastructure
As metioned in elasticsearch documnets: elasticsearch is a near real time search platform. There is a slight latency (one second by default) from the time you index a document until the time it becomes searchable. But sometimes when you have limitation of CPU, and JVM, you need to reduce the index refresh time, which may result in delay of data shipping. Overall, if you have enough capacity, we could see elasticsearh is Near Realtime.
Before we get into detail of elasticsearch, we need to understand couple of concepts, including the defination of cluster, node, index, type, document, shards and replicas.
Cluster
A cluster is a collection of one or more nodes that together holds your entire data and provides federated indexing and search capabilities across all nodes. In AWS version elasticsearch, it usually gives cluster different domain names to seprate differentiate clusters. And also each cluster can have particular access policy.
Node
In AWS version elasticsearch, node can be categorized as Dedicated Master Node and Data Node. By default, you will have three dedicated node(Split Brain).
The master dedicated node function as:
- Track all nodes in the cluster;
- Track the number of indices in the cluster;
- Track the number of shards belonging to each index;
- Maintain routing information for nodes in the cluster;
- Update the cluster state after state changes, such as creating an index and adding or removing nodes in the cluster;
- Replicate changes to the cluster state across all nodes in the cluster;
- Monitor the health of all cluster nodes by sending heartbeat signals, periodic signals that monitor the availability of the data nodes in the cluster.
Index
An index is a collection of documents that have somewhat similar characteristics. Naming the index is very important, since indexes are identified by their names (that must be all lowercase) and these names are used to refer to the index when performing indexing, search, update, and delete operations against the documents in it. Normally, if the data are roughly indetical, you can name the indices by time. For example: logs-%{+YYYY.MM.dd} by day or logs-%{+YYYY.MM} by month. That really depends on how you are going to manage your data, that is to say, what is your data retention policy, how frequent to merge or rollover your indices. If the data are huge different and you just give one index name, it will be very hard to manage or sometimes it may result in mapping issue.
Document
A document is a basic unit of information that can be indexed.
Shards
Sharding is important for two primary reasons:- It allows you to horizontally split/scale your content volume
- It allows you to distribute and parallelize operations across shards (potentially on multiple nodes) thus increasing performance/throughput
Replicas
Replication is important for two primary reasons:- It provides high availability in case a shard/node fails. For this reason, it is important to note that a replica shard is never allocated on the same node as the original/primary shard that it was copied from.
- It allows you to scale out your search volume/throughput since searches can be executed on all replicas in parallel.
Elasticsearch cluster shards
The below graph shows how does shard work in elasticsearch.
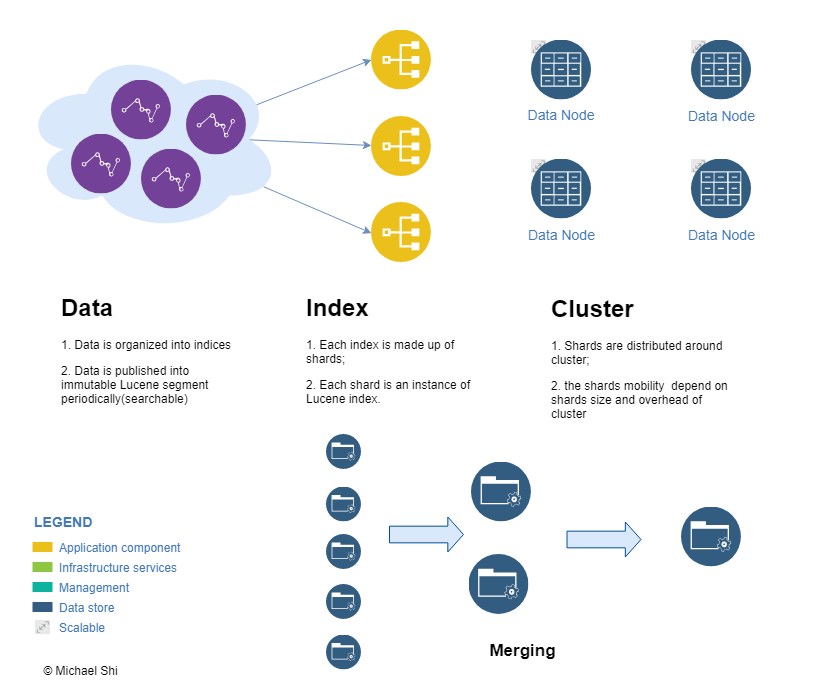
Normally, the data comes from filbeat and then pipe into logstash. Once logstash clean the data into analized format, it forwards data into elasticsearch. When logstash output data by using elasticsearch output plugin into elasticsearch, the data are orgnized by indices.
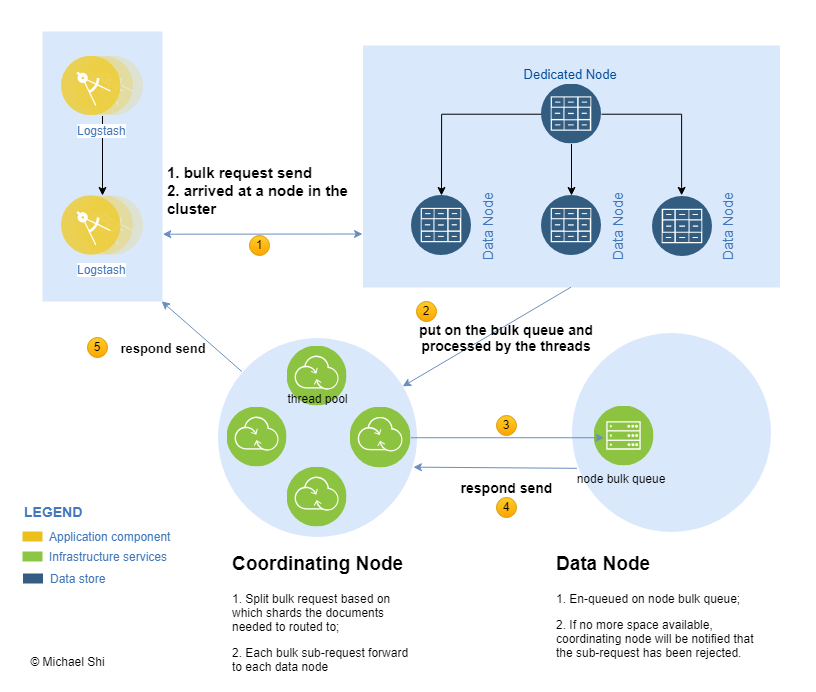
Elasticsearch cluster bulk request
Elasticsearch cluster setup
- Number of shards
- Disk Space
- CPU
Elasticsearch cluster useful APIs
1 | curl -X GET 'localhost:9200/_cat/indicies?v' |